Как выделить шаблоны из набора текстов
В этой короткой заметке расскажу о небольшом инструменте, который способен выделить шаблоны из набора текстов. К чему это вообще в 2026 году, когда мы тут делаем агентов, вайбкодим и фармим стони тысяч просмотров на сгенерированных видосах? Вот на вскидку несколько:
- если вы строите обычные классификаторы, то выделенные шаблоны помогут вам понять, на что ваш классификатор будет обращать в первую очередь;
- шаблоны позволят вам нагенерить текстов, которые не будут случайно сломаны семантически, потому что грамматики под вашим контролем;
- оценить сложность и разнообразие синтаксиса — если большинство текстов укладываются в грамматику, то скорее всего синтаксически это не очень сложные тексты;
- шаблоны могут помочь в разметке и в выявлении шума: можно обходить ветви шаблона (что быстрее, потому что это структура) и сразу назначать/подтвержать класс;
- вам просто нравятся такие штуки.
Прикольно еще то, что он работает в unsupervised режиме, в отличие от генератора регэкспов stree. Инструмент называется Gitta, который по набору текстов генерит дерево шаблонов — направленный ацикличный граф, где каждый узел представляет шабон. В шаблонах есть слоты — места, где вставляются шаблоны-потомки. Чем ближе к корню шаблон, тем он более общий. Листья деревье — шаблоны без слотов, т. е. просто тексты. Если интересно, как это работает, алгоритм описан в статье.
Установка
За 6 лет существования репы, автор так и не сделал не то, что пакета на pypi, но даже setup.py, поэтому Гитту придется скачивать с гита.
git clone https://github.com/twinters/gitta.git
Устанавливаем библиотеки
# pip install numpy==1.26 nltk sortedcontainers datasets
Учим шаблоны из текстов
Я буду экспериментировать с тем, что мне ближе — с суицидом.
Когда мы размечали датасет, то даже глазом заметили, что класс «мысли о суициде» ну прям очень шаблонный. Давайте его и возьмем. Мы ограничимся длиной в 10 токенов и 50 случайными текстами, ниже узнаете, почему. Также еще уберем пунктуацию для простоты.
import sys
sys.path.append("./gitta")
from datasets import load_dataset
from string import punctuation
import pandas as pd
import random
import gitta.grammar_induction
import seaborn as sns
from matplotlib import pyplot as plt
random.seed(123)
dataset = load_dataset("psytechlab/presuisidal_antisuisidal_dataset-master")
train = dataset["train"].to_pandas()
train["len"] = train.text.apply(lambda x: len(x.split()))
texts = train[(train.label == "смерть/мысли о смерти") & (train.len < 11)].sample(50).text.to_list()
texts = ["".join([x for x in y if x not in punctuation]).lower() for y in texts]
Индукция шаблонов выполняется одной командой. Как пишет автор, дефолтные параметры и так должны работать, но приводит список, на который стоит обратить внимание. От себя добавлю, что они важны в особенности, когда вы захотите ускорить работу.
- `relative_similarity_threshold`: 0 = join slots if at least one value overlaps, 1 = never join slots unless their values 100% overlap.
- `àllow_empty_string`: True if slots are allowed to map to empty strings, False if you want at least one token from every slot. Helpful to simply and easily correct resulting grammars.
- `max_depth`: The maximum depth the internal template tree is allow to become at any point, thus also limiting how deep your grammar can be.
- `use_best_merge_candidate`: Forces GITTA to work optimally, but lose some performance. Turning this boolean off can increase speed, but might result in slightly off grammars.
- `prune_redudant`: Prunes nodes of the template tree if all their children are already covered by other sibling nodes. Turning this off might make the grammar have more paths to generate the same string.
reconstructed_grammar = gitta.grammar_induction.induce_grammar_using_template_trees(
texts,
relative_similarity_threshold=0.1,
)
И вот, что у нас получилось:
print(reconstructed_grammar.to_json())
{
"origin": [
"<H> самоубийства",
"<L> я не хочу <M>",
"<N> меня <O>",
"<P> меня <Q> мысли о самоубийстве",
"<R> я <S>",
"а <T> у меня <U>",
"в общем я уже несколько месяцев думаю о самоубийстве",
"если бы я умерла всего этого не было бы",
"и в последнее время я начал часто задумываться о смерти",
"и меня всё чаще подталкивает на мысль покончить жизнь самоубийством",
"и тут меня посетила мысль самоубийства",
"мне <E>",
"мне хочется умереть чтобы прекратить это",
"может <B> умереть",
"мысли о суициде <C>",
"наверное <I> что я <J> думаю о <K>",
"но что же мне делать как не думать о самоубийстве",
"остается только покончить с собой",
"так и хочется наложить на себя руки",
"у меня возникает желание уйти из этого мира",
"у меня два варианталибо уходить из дома либо суицид",
"я <F> не хочу жить <G>",
"я думаю <D>"
],
"N": [
"от самоубийства",
"последнее время"
],
"O": [
"отталкивает лишь мама",
"посещают суицидальные мысли"
],
"T": [
"",
"вчера"
],
"U": [
"мысли как закончить жизнь",
"появилось желание умереть"
],
"F": [
"",
"поняла что больше"
],
"G": [
"",
"дальше"
],
"I": [
"потому",
"с того"
],
"J": [
"серьезно",
"слишком много"
],
"K": [
"смерти",
"суициде"
],
"R": [
"",
"и",
"но"
],
"S": [
"<BC> о самоубийстве",
"<BD> хочу умереть <BE>",
"<Z> о суициде <BA>",
"буду честен зачем врать когда решился покончить с собой",
"думаю моя смерть их только обрадует",
"испытываю тягу к смерти",
"каждый день молю бога о смерти",
"не хочу жить дальше",
"не хочу жить не хочу совершенствоваться не хочу развиваться",
"не хочу покончить с собой а просто умереть",
"хочу <BB>",
"хочу покончить с собой хочу быть с парнем",
"хочу умерть просто умереть и все",
"яростный самоубийца"
],
"L": [
"мне 24 года и жить",
"но боюсь того что"
],
"M": [
"",
"жить"
],
"C": [
"не выходят у меня из головы",
"посещаю меня уже несколько лет"
],
"B": [
"быть на это раз я смогу",
"мне не лечится и быстрее"
],
"P": [
"",
"у"
],
"Q": [
"неоднократно возникали",
"часто посещают"
],
"H": [
"мне кажется это всётаки дойдёт до моего",
"с детсве меня посещали мысли о"
],
"E": [
"17 и у меня снова обострение в желании сдохнуть",
"сейчас очень плохо что я постоянно думаю о самоубийстве"
],
"D": [
"моя смерть их только обрадует",
"о суециде мне очень хочется умереть"
],
"BC": [
"задумываюсь",
"каждый день думаю",
"начала думать",
"уже мечтаю"
],
"Z": [
"думал",
"очень давно думаю"
],
"BA": [
"еще года 2 назад",
"лет с 13"
],
"BD": [
"",
"просто"
],
"BE": [
"cqpic",
"бляьььь"
],
"BB": [
"покончить с собой хочу быть с парнем",
"умереть что бы не видеть эту жизнь"
]
}
Генерация текстов
Теперь, когда у нас есть выученный шаблон, мы можем сгенерировать всевозможные тексты по этим шаблонам. Для этого можно использовать метод generate_all().
all_generations = reconstructed_grammar.generate_all()
all_generations
{"а вчера у меня мысли как закончить жизнь",
"а вчера у меня появилось желание умереть",
"а у меня мысли как закончить жизнь",
"а у меня появилось желание умереть",
"в общем я уже несколько месяцев думаю о самоубийстве",
"если бы я умерла всего этого не было бы",
"и в последнее время я начал часто задумываться о смерти",
"и меня всё чаще подталкивает на мысль покончить жизнь самоубийством",
"и тут меня посетила мысль самоубийства",
"и я буду честен зачем врать когда решился покончить с собой",
"и я думал о суициде еще года 2 назад",
"и я думал о суициде лет с 13",
"и я думаю моя смерть их только обрадует",
"и я задумываюсь о самоубийстве",
"и я испытываю тягу к смерти"}
len(all_generations)
116
all_generations = [str(x).replace("\"", "") for x in list(all_generations)]
set(all_generations) - set(texts)
{'а вчера у меня мысли как закончить жизнь',
'а у меня появилось желание умереть',
'и я буду честен зачем врать когда решился покончить с собой',
'и я думал о суициде еще года 2 назад',
'и я думал о суициде лет с 13',
'и я думаю моя смерть их только обрадует',
'и я задумываюсь о самоубийстве',
'и я испытываю тягу к смерти',
'и я каждый день думаю о самоубийстве',
'и я каждый день молю бога о смерти',
'и я начала думать о самоубийстве',
'и я не хочу жить дальше',
'я яростный самоубийца'}
len(set(all_generations) - set(texts))
66
Всего у нас получилось 116 текстов, 66 из которых новые. Есть, конечно, забавные тексты типа «я яростный самоубийца», но в целом тексты то, что надо.
Про время работы
Теперь про то, почему у нас максимум 10 токенов. Если в наборе появляются слишком длинные тексты, то алгоритм начинает очень жоско тупить. Я не разбирал его на кусочки, но полагаю, что чем больше длина, тем больше вариантов шаблонов надо проверять. При этом, видимо, варианты особо не режутся, потому что время работы явно не по линии увеличивается. Вот в таких случаях вам понадобится тюнинг параметров.
Чтобы у вас было представление о времени работы, я замерил алгоритм на разных максимальных длинах текстов и количестве текстов в выборке.
report = []
def func(texts):
reconstructed_grammar = gitta.grammar_induction.induce_grammar_using_template_trees(
texts,
relative_similarity_threshold=0.1,
)
return reconstructed_grammar
for max_len in [10, 13, 17]:
for sample_num in [10, 25, 50, 75, 100]:
for _ in range(5):
while True:
texts = train[(train.label == "смерть/мысли о смерти") & (train.len < max_len+1)].sample(sample_num).text.to_list()
t1 = time()
try:
reconstructed_grammar = func(texts)
except AssertionError:
continue
t2 = time()
ellapsed_time = t2 - t1
all_generations = reconstructed_grammar.generate_all()
new_text_num = len(set(all_generations) - set(texts))
report.append( (max_len, sample_num, ellapsed_time, new_text_num) )
break
df = pd.DataFrame(report, columns = ["max_len", "sample_num", "time", "new_text_num"])
sns.lineplot(data=df, x="sample_num", y="time", hue="max_len", err_style="bars")
plt.yticks([60*i for i in range(15)])
plt.xticks([10, 25, 50, 75, 100])
plt.grid(True)
print()
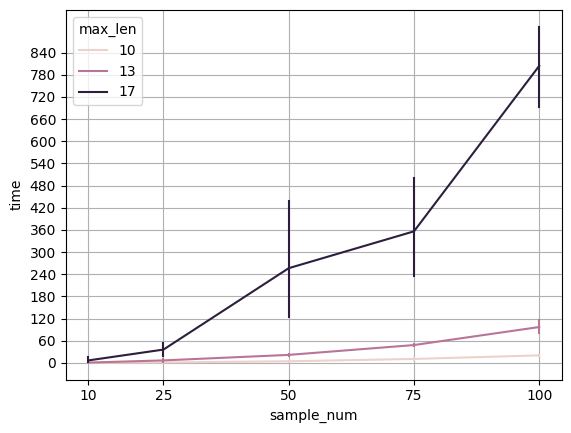
Как видите, разница между 13 и 17 на хоть как-то значимых объемах колоссальна. Если хотите поупражняться в алгоритмах, то вот вам хорошая задача. Сердце Гитты — алгоритм Вагнера-Вишера. К ускорению можно подойти с трех сторон: точно ли Питон хороший выбор для алгоритма, можно ли сделать какие-нибудь оптимизации на уровне кода, ну и как можно модифицировать алгоритм, может вообще другой подобрать. Может быть дело не совсем в Вагнере-Вишере, короче, задача богатая.
Кстати, во взятом мной классе текстов, не длиннее 10 токенов, полторы тысячи, что составляет 50 процентов от общего объема. Судя по графику, на это потребуется заметное время, но зато получится представление о структуре половины текстов. Кстати, напомню, что можно еще покрутить параметры, о которых говорил в начале.
На последок хочу подкинуть лайфхак. Некоторые токены в тексте можно обобщить, чтобы упростить выделение. Например, мы точно знаем, что в датасете очень часто люди пишут в духе «мне столько лет и у меня такая-то проблема/желание». Каждое число считается отдельным токеном, что может помешать сделать из этой фразы шаблон. Простой регуляркой re.sub([0-9]+, '<NUMBER>') можно решить этот вопрос. Правда в этом случае вы не узнаете (если бы не знали), после каких числе пишется «лет» или «года». Сюда же относится явное выделение фраз, как отдельных токенов. Можно пойти еще дальше и предобработать текст так, чтобы выделять шаблоны со специальными признаками. Если, скажем, вас интересуют существительные, а связь между ними вы хотите вынести за скобки, тогда можете взять pos-теггер и все глаголы в тексте заменить на
Напоследок
К сожалению, документация у либы, как setup.py — ее нет. Есть только два ноутбука, которые и лежат в основе этого поста. Вторая фича, которую подсвечивает автор, это возможность описать шаблон самому. Сделать это можно вот так:
from gitta.context_free_grammar import ContextFreeGrammar
rules = {
'origin': '<hello>, <location>!',
'hello': ['Hello', 'Greetings', 'Howdy', 'Hey'],
'location': ['world', 'solar system', 'galaxy', 'universe']
}
grammar = ContextFreeGrammar.from_string(rules)
original_dataset = grammar.generate_all_string()
dataset = list(original_dataset)
dataset
['Hey, galaxy!',
'Hello, world!',
'Hey, universe!',
'Hello, universe!',
'Howdy, universe!',
'Greetings, universe!',
'Greetings, solar system!',
'Howdy, solar system!',
'Greetings, world!',
'Hello, solar system!',
'Howdy, world!',
'Hello, galaxy!',
'Howdy, galaxy!',
'Greetings, galaxy!',
'Hey, world!',
'Hey, solar system!']
На этом у меня всё.