БЯМки разгребают беклог. Как я вайбкодил имплементацию по статье
Обучение с учителем на половину. Готов поспорить, что почти никто из вас не слышал про эту древнюю технологию. Другое ее название — PU-learning. Я сам про нее узнал чисто случайно, захотелось испытать и вот руки дошли.
PU значит positive-unlabeled, то есть это методы о том, как обучать классификаторы, имея разметку только целевого класса. Это полезно в ситуациях, когда у вас разметка дорогая или у вас просто денег нет: было бы круто не тратиться на разметку «отрицательных» примеров — таких, которые не содержат интересующий феномен. Кроме денег, можно было бы сэкономить время, раз не надо размечать «отрицательные» примеры.
Наглядно объясню на том, что мне ближе. Вот хочу я обучить классификатор депрессии по текстам. Допустим мне несказанно повезло и я собрал тексты из соц. медия людей, у которых я видел бумажку с депрессивным диагнозом — самый надежный маркер целевой переменной. Таких текстов вряд ли будет много и это будет мой позитивный набор. Поскольку я не могу от других пользователей требовать бумажку есть ли у него такой диагноз или нет, для меня их тексты будут неразмеченным набором. И вот стоит задача по кучке «проверенных» и море неразмеченных текстов обучить классификатор депрессии.
Как я сказал выше, мне просто стало интересно попробовать, как оно работает. В закладках у меня висела статья “Text Classification without Negative Examples Revisit”. Она мне понравилась внятным описанием всех алгоритмов в виде псевдокода, которые авторы предлагали. Суть метода пересказывать не буду, можете сами посмотреть, если интересно. Там же в начале есть формальное описание задачи PU-обучения. Скажу лишь, что это именно «древние» технологии, завязанные на bag-of-words, классическом ML, вот это всё. Сама статья закрыта, но вы можете воспользоваться сервисом, который начинается на sci, кончается на hub. Висела она у меня уже примерно пару лет потому что имплементить эти алгоритмы вечно не было времени, ну вы понимаете.
И тут я такой «Хмм, а может какой-нибудь Клод с этим справится?». Дал на вход ему статью и попросил написать код на питоне на основе псевдокода. За исключением одной ошибки с типами матриц, код запустился сразу, БЯМ заботливо сгенерила код для тестового запуска. Поскольку код генерился по алгоритму, БЯМ часто даже переменные называла так, как в статье, что удобно для проверки.
Первое, что я решил попробовать, это дать алгоритму больше, чем 10 текстов. Сразу всплыли проблемы оптимизации. Вот самая серьезная:
for j, feature in enumerate(feature_names):
# Количество документов, содержащих признак f_j
n_P_fj = np.sum(X_P_dense[:, j] > 0)
n_U_fj = np.sum(X_U_dense[:, j] > 0)
# Нормализация
if X_P_dense.shape[0] > 1:
max_P = np.max([np.sum(X_P_dense[:, k] > 0) for k in range(X_P_dense.shape[1])])
min_P = np.min([np.sum(X_P_dense[:, k] > 0) for k in range(X_P_dense.shape[1])])
else:
max_P = min_P = n_P_fj
if X_U_dense.shape[0] > 1:
max_U = np.max([np.sum(X_U_dense[:, k] > 0) for k in range(X_U_dense.shape[1])])
min_U = np.min([np.sum(X_U_dense[:, k] > 0) for k in range(X_U_dense.shape[1])])
else:
max_U = min_U = n_U_fj
Здесь важна именно структура кода, а не что конкретно вычисляется. Видите feature_names? Это словарь, который определяет размерность векторов. Когда у вас текстов мало, словарь тоже не очень большой, поэтому на 10 текстах все будет работать быстро. Но если текстов у вас хотя бы около тысячи, то из-за четырех, Карл, внутренних циклов, которые пробегаются, КАРЛ, по размерности словаря — X_*_dense плотные не в смысле, что там размерность маленькая, а в смысле, что это не разреженные матрицы — то ждать вы будете очень долго.
А все почему. Вот эти переменные max_* зависят от feature_names в случае, если матрица X__dense не имеет строк (if X_U_dense.shape[0] > 1:). Так сетка, видимо, перестраховалась. Но дело в том, что эти две матрицы не могут быть пустыми, это буквально базовые входные данные. Поэтому вычисление этих max_ можно вынести за цикл и всё станет резко лучше. А сгенерено так потому что сетка идет по псевдокоду буквально.
Есть еще места, которые слишком буквально идут по алгоритму из статьи. Например, в одном месте вместо того, чтобы на матрицах считать косинусное расстояние для набора документов, оно считается циклом — так показано в алгоритме в статье. Другой пример, найдите отличия:
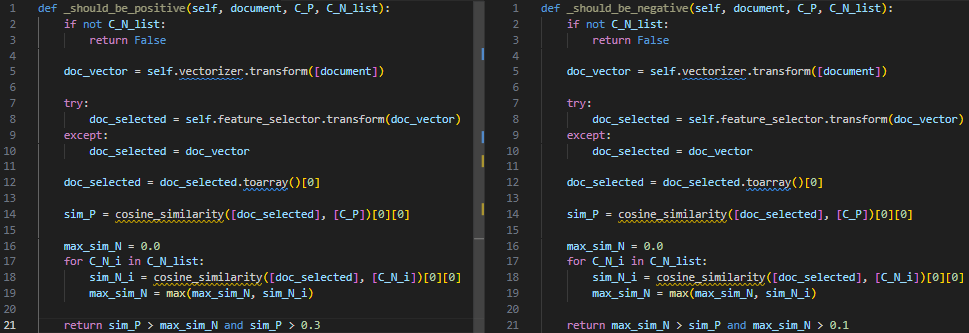
Все потому что так в алгоритме написано. Однако эти два упомянутые прикола особо не повлияли на время. Узкое горло — это расчет отбор признаков с помощью mutual_info_classif, потому что признаковое пространство, как водится, тысячи.
Но что сеть решила проигнорировать, так это правила определения порогов. На скрине выше они захардкожены в последних строках функций, хотя на самом деле в статье описаны правила их определения. Более того, это подается как «фишка» статьи. Вот так вот. Обнаружил я это уже после того, как на радостях запустил тестовый эксперимент.
Проверить код я решил на 20_new_groups по таким топикам: alt.atheism, comp.graphics, rec.motorcycles, sci.space. Специально подобрал так, чтобы было проще. Меня в первую очередь интересовал вопрос: как будет изменяться качество классификатора с ростом числа позитивных примеров. Так же будет понятно, сколько примерно нужно позитивных данных, чтобы получить что-то приличное. Неразмеченной частью выступали все остальные топики и 20 процентов позитивного класса. Объем это части не менялся в рамках одного класса. Клод в обертку впихнул несколько базовых классификаторов, я оставил SVM, который был по дефолту. Вот, что у меня получилось.
| positive_class | positive_example_num | train_time | precision | recall | f1 | acc | unlabeled_example_num | |
|---|---|---|---|---|---|---|---|---|
| 0 | alt.atheism | 100 | 215.72 | 1 | 0.0658307 | 0.123529 | 0.801333 | 2159 |
| 1 | alt.atheism | 200 | 170.411 | 1 | 0.0909091 | 0.166667 | 0.806667 | 2159 |
| 2 | alt.atheism | 300 | 177.722 | 0.989583 | 0.297806 | 0.457831 | 0.85 | 2159 |
| 3 | alt.atheism | 384 | 186.706 | 0.98 | 0.460815 | 0.626866 | 0.883333 | 2159 |
| 4 | comp.graphics | 100 | 211.398 | 1 | 0.0616967 | 0.116223 | 0.756667 | 2138 |
| 5 | comp.graphics | 200 | 221.515 | 0.992 | 0.318766 | 0.48249 | 0.822667 | 2138 |
| 6 | comp.graphics | 300 | 228.147 | 0.989583 | 0.488432 | 0.654045 | 0.866 | 2138 |
| 7 | comp.graphics | 400 | 166.637 | 0.965116 | 0.640103 | 0.769706 | 0.900667 | 2138 |
| 8 | comp.graphics | 467 | 208.89 | 0.969466 | 0.652956 | 0.780338 | 0.904667 | 2138 |
| 9 | rec.motorcycles | 100 | 223.426 | 0 | 0 | 0 | 0.734667 | 2135 |
| 10 | rec.motorcycles | 200 | 229.229 | 1 | 0.0301508 | 0.0585366 | 0.742667 | 2135 |
| 11 | rec.motorcycles | 300 | 189.917 | 1 | 0.231156 | 0.37551 | 0.796 | 2135 |
| 12 | rec.motorcycles | 400 | 195.708 | 1 | 0.364322 | 0.53407 | 0.831333 | 2135 |
| 13 | rec.motorcycles | 478 | 159.393 | 0.985 | 0.494975 | 0.658863 | 0.864 | 2135 |
| 14 | sci.space | 100 | 219.281 | 1 | 0.00761421 | 0.0151134 | 0.739333 | 2136 |
| 15 | sci.space | 200 | 174.334 | 1 | 0.0304569 | 0.0591133 | 0.745333 | 2136 |
| 16 | sci.space | 300 | 183.202 | 0.982456 | 0.142132 | 0.248337 | 0.774 | 2136 |
| 17 | sci.space | 400 | 232.199 | 0.982143 | 0.279188 | 0.434783 | 0.809333 | 2136 |
| 18 | sci.space | 474 | 211.515 | 0.983516 | 0.454315 | 0.621528 | 0.854667 | 2136 |
Итого видим, что во всех случаях при минимуме данных в 100 штук получается супер точный, но не слишком чувствительный классификатор, что в целом логично. Что-то приличное получается, когда объем позитивного класса пересекает отметку в 400 примерами. И всё это при том, что порог у нас фиксированный. Я считаю, что это очень неплохо, учитывая, что сетка решила бахнуть захардкоженый порог.
Наверное, если б я посидел по дольше, то у меня вообще всё было четко: и оптимизация была б на месте, и пропусков алгоритма не было. Не знаю. В любом случае, очередной раз отмечаем, что за сетками надо проверять. Если проблемы оптимизации сразу бросаются в глаза, то вот некоторые «упрощения» можно не заметить даже если алгоритм использовать на реальной задаче.
Тем не менее я наконец-то смог закрыть двухлетний гештальт и посмотрел вживую на pu-learning. Ручная реализация у меня заняла бы несколько часов, а Клод сделал мне «заготовку» за минуту.
Если хотите больше погрузиться в тему PU-обучения, то вот вам небольшой пост на Хабре 2020 года и обзор 2018 года, он самый цитируемый. Еще к нему нашел репу, где чуваки в ноутбуках разные алгосы из обзор сделали. Есть еще репа с пакетом, который можно установить через pip. В нем есть два PU-алгоса.