Аспирантские флешбеки. Проверяю гипотезу о локальной внутренней размерности как границы сжатия векторного пространства

Недавно открыл вот эту статью, где увидел вот такую картинку. На ней показано распределение локальных внутренних размерностей (ЛВР далее) для некоторых датасетов, среди которых есть SIFT1M. Этот датасет — частый гость в статьях про поиск ближайших соседей. Вы спросите «И че?». Первая тема моего диссера была как раз по knn. Считаю своей главной находкой то, что многие эмбеддинги можно довольно сильно сжать каким-нибудь PCA, при этом не особо теряя в качестве поиска. Правда, понять, где предел этого сжатия я так и не смог, потому тему решил задвинуть. Но вот нашлась интересная гипотеза.
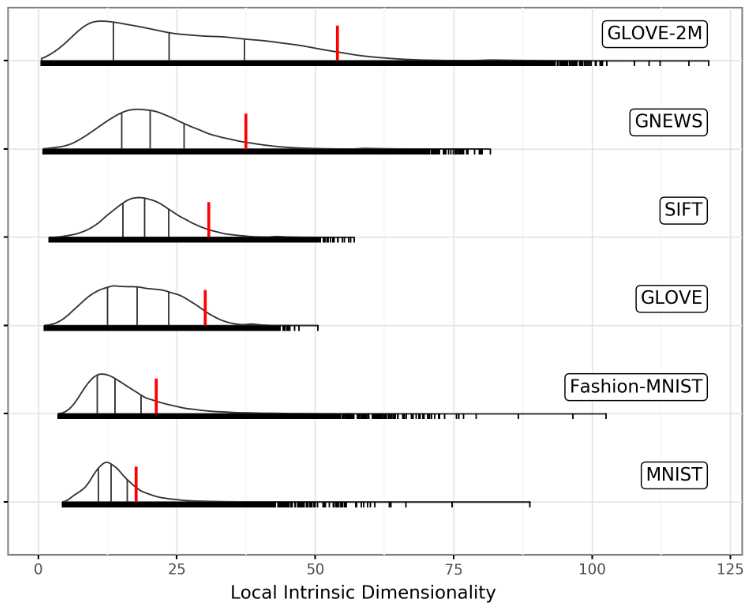
Так что в этой картинке особенного? Распределение ЛВР Сифта заканчивается как раз там, где в моих экспериментах происходит молниеносное падение качества поиска. Подумалось, может быть чем ближе размерность сжатия приближается к этому распределению, тем сильнее страдает качество. В статье я рассматривал глобальную внутреннюю размерность, а это, как оказалось в некоторых случаях, либо медиана, либо среднее локальных. На картинке выше можно как раз медианы найти. Эти значения слишком далеки от точки падения качества поиска.
На случай, если вы хотите узнать, что такое ЛВР, определение можно найти внизу третьей страницы статьи. Я приведу интуицию авторов: чем больше это число, тем труднее определить истинного ближайшего соседа для конкретной точки. Можно сказать, что это «сложность» каждого запроса.
С Сифтом всё понятно, поэтому я собрал по-быстрому эксперимент с другими эмбеддингами.
Материалы и описание эксперимента
Не хотелось тратить много времени, поэтому пошел смотреть эмбеддинги в HF. Нашел три датасета:
- Remsky/Embeddings__Ultimate_1Million_Movies_Dataset — эмбеддинги названий фильмов, полученные с помощью nomic-embed-text с размерностью 768.
- CShorten/ArXiv-ML-Abstract-Embeddings — эмбеддинги абстрактов статей с архива, полученные с помощью sentence-transformers/paraphrase-MiniLM-L6-v2 с размерностью 384.
- Cohere/wikipedia-22-12-simple-embeddings — эмбеддинги заголовка и текста статьей с Википедии на «простом английском», полученные с помощью проприетарной модели multilingual-22-12 от cohere.ai с размерностью 768.
ЛВР считал с помощью пакета scikit-dimensions, конкретно с помощью MLE, как у авторов статьи. Причем интересовали меня максимальные знаения. Считал я по 5 раз для разного количества семплов. Под капотом используется точный поиск, который с определенного количества данных просто не завершается в разумное время.
Замерял два варианта реколов:
- 1R-1 — сколько раз истинно ближайший сосед оказывался на первом месте в выдаче.
- 1R-10 — сколько раз истинно ближайший сосед оказывался среди выдачи топ-10.
Датасет для замеров качества работы kNN состоит из 4 частей:
- тренировочная выборка — некоторые алгоритмы kNN тренируемы, как, например, те, что используют k-means под капотом.
- основная выборка, она же база — эта выборка индексируется алгоритмом.
- запросная выборка — для нее как раз ищутся соседи.
- упорядоченные истинные индексы ближайших соседей из базы для каждого примера из запросной части — по этой части как раз и оценивается результат работы алгоритма.
У меня есть специальная функция, которая позволяет из любого набора вектором сделать такой датасет. Чтобы посчитать истинные индексы, я использую HNSW. Да, это неточный поиск, но у него очень мало ошибок, а времени экономит массу.
Теперь как проводится мой эксперимент:
- По циклу проходимся по размерности от почти исходной до нулевой с определенным шагом (у меня был 50).
- Сжимаем все выборки векторов до размерности, полученной на шаге 1.
- Замеряем метрики с помощью HNSW.
Опять, я готов на ошибки NHSW, потому что ExactSearch ждать долго. Сжимал я векторы с помощью PCA из faiss. Также, как и k-means, в этой либе он работает много быстрее, чем в sklearn. На всякий случай вот как это делается:
import faiss
pca = faiss.PCAMatrix(data.shape[1], compressed_dim)
pca.train(data)
data_ = pca.apply(data)
Результаты
Начнем с замеров ЛВР.
| (dataset, num_samples) | (‘max_lid’, ‘mean’) | (‘max_lid’, ‘std’) | (‘max_lid’, ‘max’) |
|---|---|---|---|
| (‘arxiv’, 1000) | 78.1844 | 17.3272 | 104.943 |
| (‘arxiv’, 10000) | 125.99 | 17.9452 | 152.765 |
| (‘arxiv’, 50000) | 162.874 | 20.584 | 195.856 |
| (‘movies’, 1000) | 118.118 | 42.6601 | 188.498 |
| (‘movies’, 10000) | 132.109 | 15.6362 | 158.278 |
| (‘movies’, 50000) | 197.65 | 22.5655 | 231.239 |
| (‘wiki’, 1000) | 92.5507 | 8.92258 | 108.113 |
| (‘wiki’, 10000) | 132.155 | 5.84565 | 138.64 |
| (‘wiki’, 50000) | 158.337 | 14.8397 | 180.787 |
Бросается в глаза, что максимум сильно зависит от количества данных, то есть либо появляются более «сложные» точки, либо с ростом количества данных «сложность» в целом увеличивается. А может и всё вместе: рост среднего говорит в пользу второго, а высокий разброс в пользу первого. При этом ни на одном датасте не видно, чтобы среднее значение подходило к «потолку». Может быть действительно надо посчитать ЛВР для всего датасета.
А вот что получилось со сжатием:
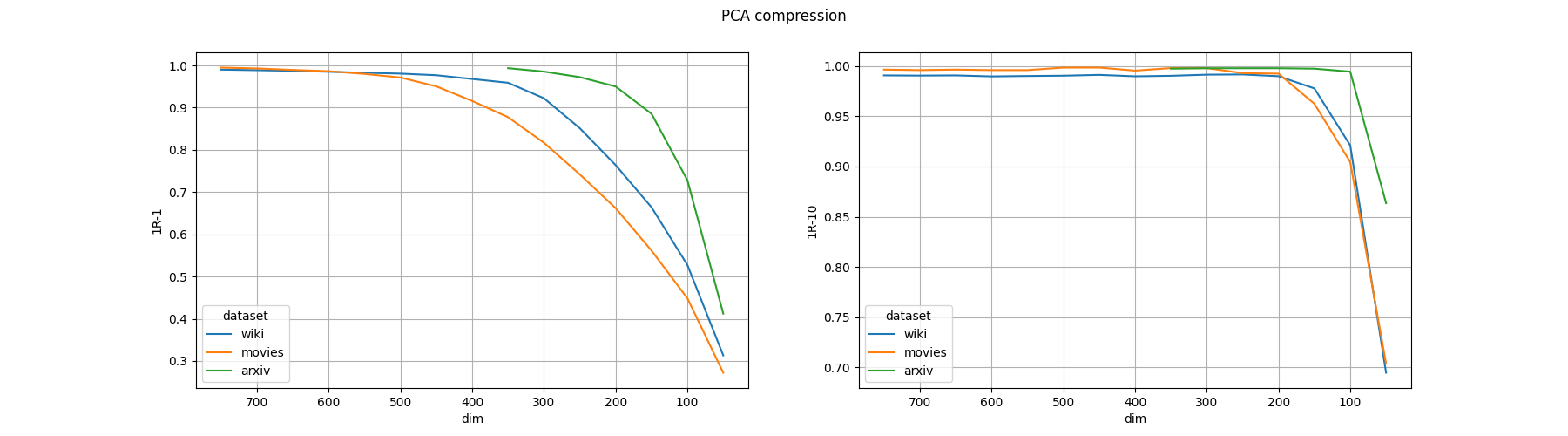
В общем, пока максимум ЛВР как-то связать с деградацией качества нельзя: насчитать максимум так, чтобы он близко находился с началом деградации качества по 1R-1, не получилось. Можно было бы сказать, что он связан с 1R-10, но у Архива эта метрика начала сильно падать между 50 и 100 размерностью, тогда как ЛВР в двух случаях был много за 100.
Отмечу сам по себе факт, что вы можете обычным PCA снизить размерность почти в двое в случае 768 эмбеддингов и держать качество поиска на 95 процентах по 1R-1, а если вам достаточно, чтобы истинный ответ находился хотя бы в топе 10, то и вовсе в 5 раз.
А я пока задвину тему обратно.